
|
Text File Localization and Internationalization |
A text file (Wikipedia) is a file that contains characters. A text file can contain any number of lines where each line contains any number of characters. A text file can either contain plain text or structured text. A plain text file can contain any characters at any order. In most cases, such files are documents that contain some text. The structured text file contains one or more records. Each record contains one or more fields. Soluling can localize both types. The simplest way to scan a plain file is to read the complete file into one Soluling row. This works well when the file size is small, and the string length of the row remains relatively small. However, when the file gets bigger storing everything in a single row gets unpractical. In that case, it is better to use segmentation.
Unlike plain text files, defined files are more like databases. They contain records. Each record contains one or more fields. Some fields, such as string fields, might need to be localized. Some other fields, such as id fields should not be localized. Soluling uses text definitions to specify the structure of a defined text file. Soluling localization tool and service support text files and data.
Soluling supports all the character encodings that Windows supports. This includes most Unicode encodings such as UTF-8, UTF-16 (big and little-endian), UTF-32 (big and little-endian), and GB 18030. All with and without BOM. In addition, Soluling supports most legacy encodings such as Windows code page, ISO code pages, Mac code pages, EBCDIC code pages, etc. Most of the time, Soluling can automatically detect the encoding of your file. However, if Soluling cannot detect the encoding, it will prompt a dialog where you can specify the encoding.
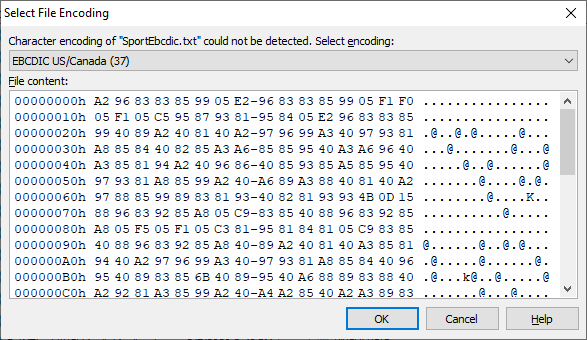
The dialog shows the beginning of the file in the hex code that might help you figure out the encoding. Select the encoding and then click OK.
When we localize a plain text file Soluling reads the whole file into one string and inserts that string into the project. Let's have an example.
Sports 1. Soccer Soccer is a sport played between two teams of eleven players with a spherical ball. Team contains 10 field players and a goalie. Soccer originates from England. 2. Ice hockey Ice hockey is a team sport played on ice, in which skaters use sticks to direct a puck into the opposing team's goal. Team contains 5 field players and a goalie. Ice hockey originates from Canada. 3. Basketball Basketball is a team sport in which two teams of five players try to score points by throwing a ball through the top of a basketball hoop while following a set of rules. Team contains 5 field players. Basketball originates from United States.
When you create a new project that contains the above file leave Scan mode to Scan as single string that is the default value.
When Soluling creates the project there is only one row that contains the complete text file.
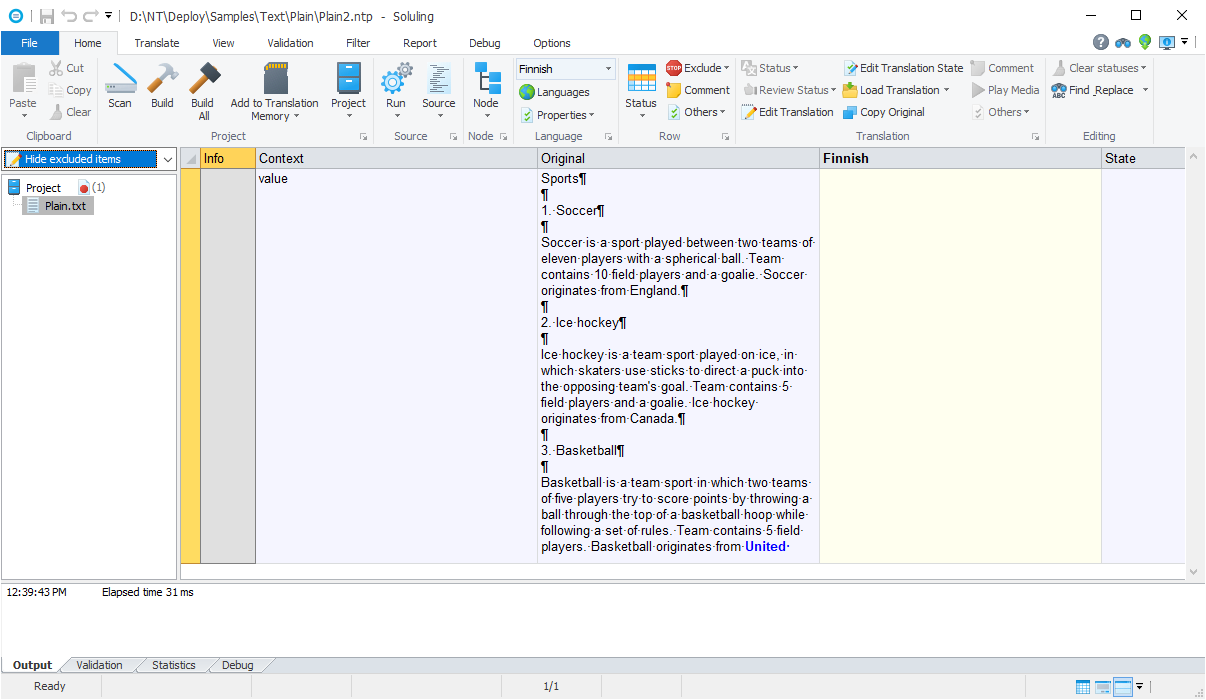
This file is relatively small, so everything fits into a single cell. However, if the file gets larger, this kind of localization gets impractical. In that case, it is better to use segmentation.
When we localize a segmented text file, Soluling reads the whole file into one string and then breaks it into segments. Each segment is added into separate rows in the project. Let's have an example.
Sports 1. Soccer Soccer is a sport played between two teams of eleven players with a spherical ball. Team contains 10 field players and a goalie. Soccer originates from England. 2. Ice hockey Ice hockey is a team sport played on ice, in which skaters use sticks to direct a puck into the opposing team's goal. Team contains 5 field players and a goalie. Ice hockey originates from Canada. 3. Basketball Basketball is a team sport in which two teams of five players try to score points by throwing a ball through the top of a basketball hoop while following a set of rules. Team contains 5 field players. Basketball originates from United States.
When you create a new project that contains the above file, set the Scan mode to Use segmentation.
When Soluling creates the project, there are multiple rows instead of one row.
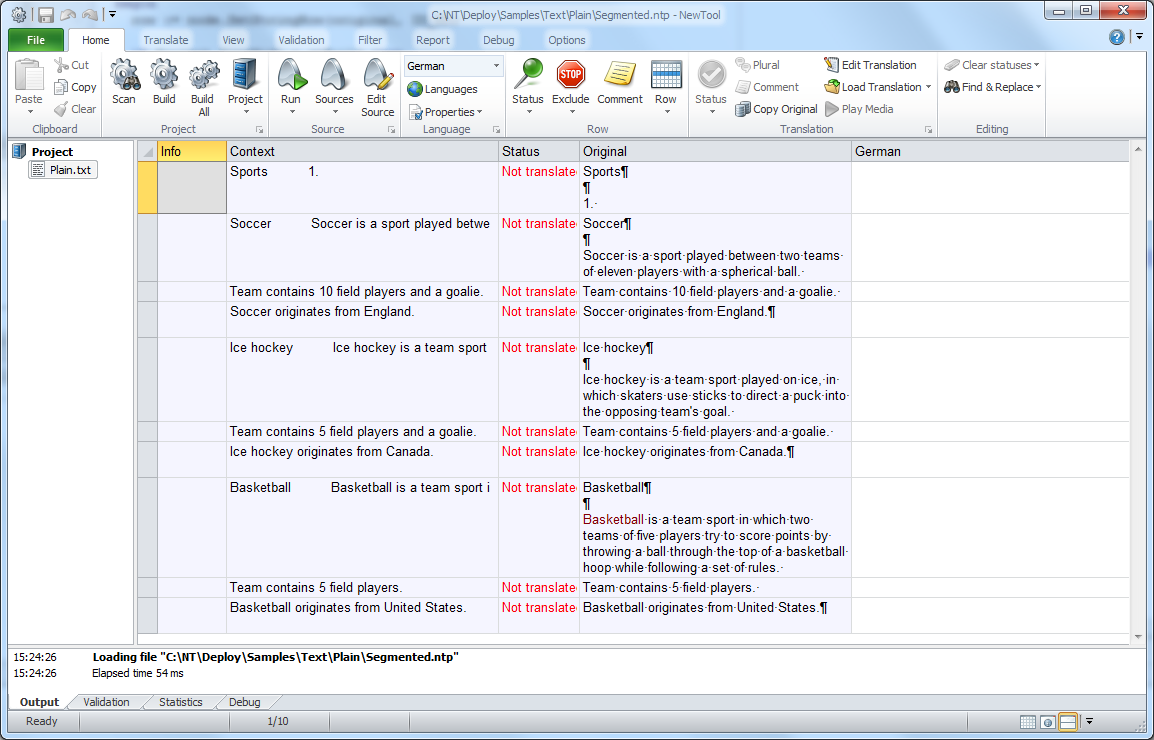
At first, this looks right, but we see that the segmentation is not completely right. There are two errors. First, there should be a segment boundary after each new line. Secondly, the header numbers (1. 2. and 3.) generate a segment break when in this case, there should not be a break. Fortunately, Soluling uses the standard segmentation rules (SRX), and we can easily modify the rules. Initially, Soluling assigns the default rules that catch most breaks and handle most exceptions. To edit the rules right click Plain.txt in the project tree and choose Options. Then select the Options sheet.
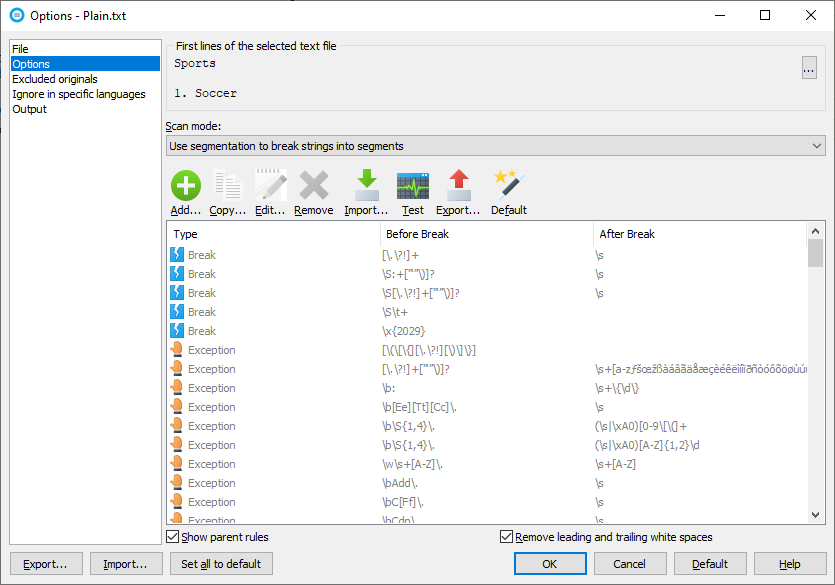
The dialog shows the current rules. Soluling contains a set of so-called default rules. Some of those rules are language-independent, and some are language-specific. Because Plain.txt's original language is English, the rules are a combination of the language-independent and English rules. To add a rule, click the Add button. There are two kinds of breaks. The first is a normal break. The second is an exception for a normal break. When using it, the segmentation engine also checks if there is an active exception for each case. If there is, then there is not a break. Exception checking takes some time. To avoid this, you can select the break to be without exception. In our sample, a new line break is without exception, so lets select Break no exception. Before break and After break fields contain the regular expression that specifies the break or exception. Enter \r\n into Before break field. Finally, you can give a description of the rule by entering any text to the Description field.
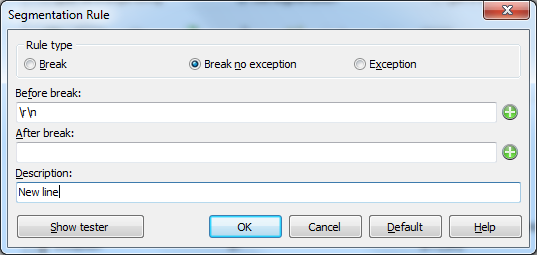
To add an exception is similar. The exception must catch <beginning of line>N.<white space> where N is a number. The following image shows the rule settings.
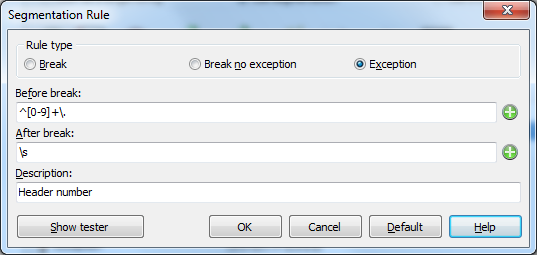
Now our rules are complete, and the source dialog looks like this.
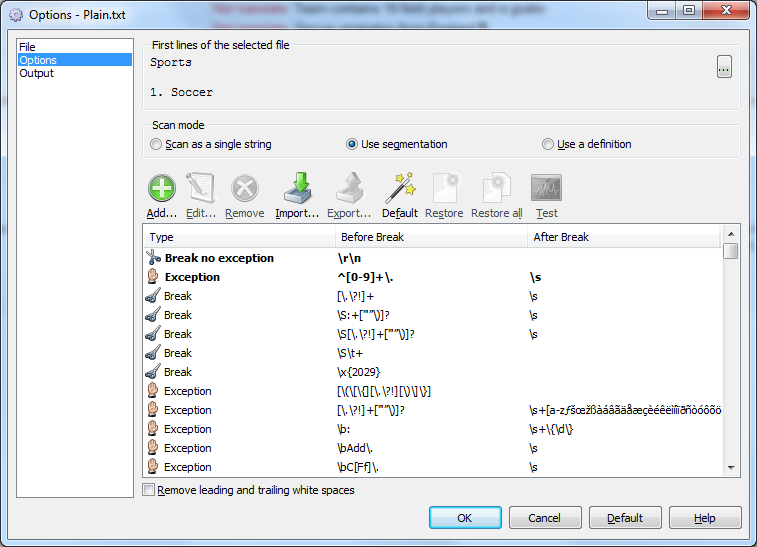
The two rules we added are custom rules, and that's why they are shown on the top of the list and are drawn on a bold typeface. Finally, click OK to close the source dialog. Now Soluling detects that you have changed the properties of the source such a way that affects scanning. This is why Soluling shows a message box that recommends rescanning. Click Yes to rescan, and finally, our file is segmented correctly.
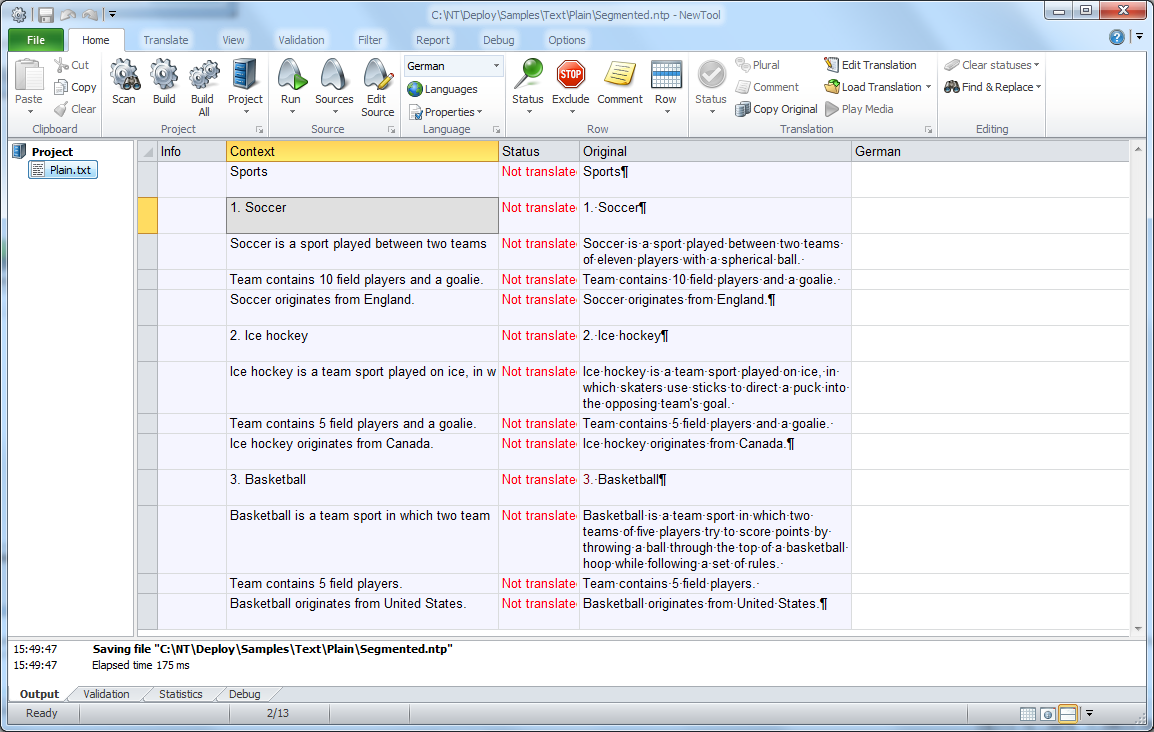
Fine-tuning the segmentation rules to match your file requires some work but compared to plain scanning segmented scanning, gives you many advantages. The project is easier to edit, and it is more unlikely that the translator will make an error.
Some text files do not contain plain text but data records. Such a file contains one or more records. Each record contains one or more fields. Let's have an example.
soccer Soccer 10 1 England Soccer is a sport played between two teams of eleven players with a spherical ball. hockey Ice hockey 5 1 Canada Ice hockey is a team sport played on ice, in which skaters use sticks to direct a puck into the opposing team's goal. basketball Basketball 5 0 United States Basketball is a team sport in which two teams of five players try to score points by throwing a ball through the top of a basketball hoop while following a set of rules. |
Each line contains one record. Each record contains five fields separated by a tab character. The first field is an id field. It must not be localized. The second field is the name field. It should be localized. The next two fields are the player count and goalie count fields. These must not be localized. The last two fields are the origin and description fields. They should be localized. Of course, we could scan this as plain text or even segmented text. The problem is that each string would contain more that one data and the translation would be difficult. It is very likely that the translator would break the format when translating. This is why we better use defined scanning. It means that we teach Soluling the format of the file by entering definition rules that define the format. Each rule specifies one field. Together the rules define the format of the record, and the parser can correctly parse the file. Like segmentation rules, the definition rules also use regular expressions.
When you create a new project that contains the above file, set Scan mode to Use definition, Soluling reads your file to analyze its format. Finally, Soluling populates the definition rules based on the result of the file analyzing.
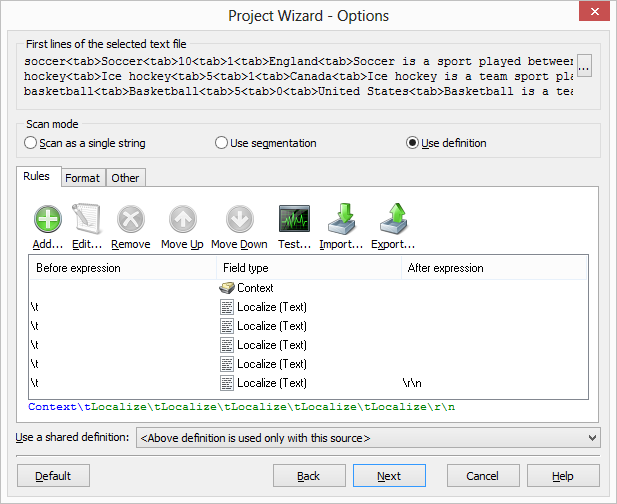
A definition is a set of field rules. Each rule specifies one field in the record. A rule can have a before and/or after expression. Expression specifies the character(s) that delimit the field values. Our sample record used tab character as a field delimiter. The first field contains the context value. We dod not need a before or after expression. The second field is the name of the sport. Here we need a before expression: \t. This regular expression specifies a table character. The rest of the fields also need a before expression. The last field is ended with a new line character. This is why we add an after expression \r\n.
We could also use only after expressions instead of before expressions. The following definition handles the same record.
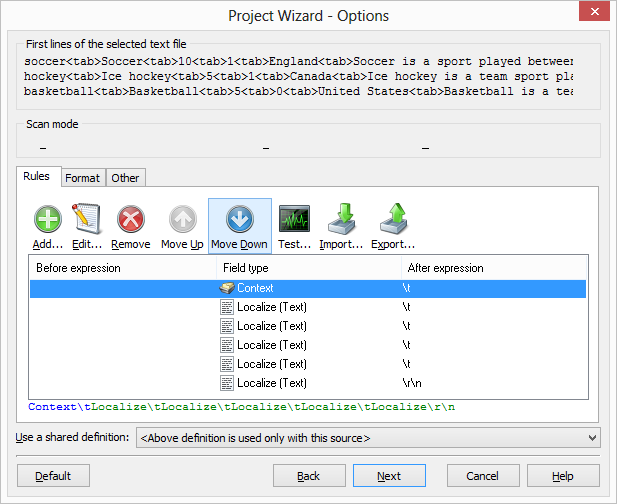
The default definition that Soluling populates, localizes all columns but the first. Our sample file also contains integer numbers (amount of field players and goalie). We do not have to locale them. Select the third column, right-click, and choose Ignore. Repeat the same for the fourth column.
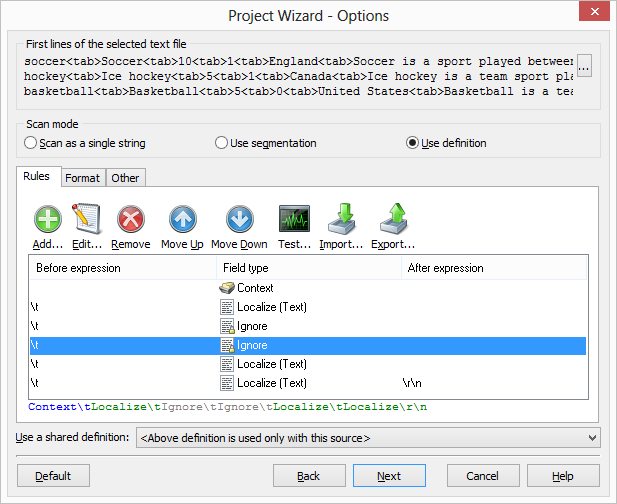
Now our definition is complete. When Soluling creates the project, it correctly scans each string field in our file.
<data-dir>\Samples\Text contains following text file sample directories:
| Directory | Description |
|---|---|
| Simple | A simple defined text file. Study this first. |
| Comment | A defined text file that contains comment fields. |
| Escape | A defined text file that contains escape characters. |
| Japanese | A defined text file that contains Shift JIS encoded Japanese text. |
| Plain | A sample text file. The directory contains two project files: Plain.ntp scans the file as a plain text. Segmented.ntp scans the file using segmentation. |
| Sport | A defined text file that contains sport data. |
You can configure how to localize your text file by selecting the item in the project tree, right-clicking, and choosing the Options menu. A source dialog appears that lets you edit the options. This source uses the following option sheets.
Settings
Read more about other data files such as XML, XSL, JSON, YAML, INI, Excel, SVG, TMX, XLIFF, text and binary files.
![]() Copyright © 2016-2026 Soluling Oy
Copyright © 2016-2026 Soluling Oy