
|
Translation Memory |
Translation memory (Wikipedia) is a database that stores translations to be used again. A translation is not a single word but a meaningful sentence. For example, a translation memory might contain "This is a car." sentence and its German translation "Das ist ein Auto." and its Japanese translation "これは車です." Whenever you have "This is a car." text in your project, Soluling can translate it automatically using the translation memory. Soluling's translation memory stores segments. The difference between a segment and a string is this. A string can contain text that can be anything from a single word to a multi-line text block. To work as optimally as possible, the text must be split into optimal pieces. This piece is a sentence. This splitting process is called segmentation.
Translation memory contains a set of original strings values. Each original value can contain one or more translations in one or more languages. In a normal case, you have multiple original values that are in the same language. This language is your source language. For each original value, there is also one translation in another language. This language is your target language. However, even this is a typical case, it is not always true. You might have original values in several languages if you translate projects from multiple languages. Similarly, you can have translations in several languages if you translate into several languages. Because of this structure, the translation memory has a direction. It has been designed to translate sentences from the original language to the target languages.
Sometimes it is useful if you could reverse the translation direction. For example, you might get a project where the original language is German, and you have to translate it into English. If you have previously done translation work from English to German, the items in your translation memory use English as the original language and German as translation. In such a case, you can turn on bidirectional searching. When in the normal search mode, translation memory looks at matches from the set of original values. In bidirectional mode, matches are also looked at from translations. This makes it possible to use two translation directions, but it also makes translation memory slower. So turn bidirectional search on only if you really need it.
When translation memory looks for matches, it can use three different match methods. They are:
| Match | Description |
|---|---|
| Perfect | A perfect match is a 100% match. The translation memory contains the same string you are looking for in the original values or in translations (if you have turned bidirectional search on). |
| Reduced | A reduced match is very close to a perfect match. |
| Fuzzy | A fuzzy match is a match of two similar strings. |
Soluling supports the following translation memories:
| Glossary | Description |
|---|---|
| Database translation memory | A local or server database that contains translation memory data in Soluling translation memory structure. Initially, Soluling contains one empty local translation memory. Database translation memory uses SQLite, MySQL or SQL Server. |
| Cloud translation memory | It has the same features as the above database translation memory, but the actual translation memory exists in the cloud, making it easily accessible to all users of your localization team no matter where they locate. |
| MyMemory translation memory | A cloud based translation memory that provides free usage up to certain limit per day. You can get translations for its large, shared translation memory, and you can store your own translations into your private translation memory. |
When you install Soluling, the setup creates a new local database translation memory that is initially empty. There are two ways to populate the translation memory. One is to start entering translations. As soon as a translation is complete, Soluling will automatically add it to the translation memory. If you have more than one translation memory, Soluling adds the translation into the main translation memory. Use Project | Project Options -> Translation memory to set the default translation memory. Another way is to import translations from translation storages or dictionaries into the translation memory.
Once you have items in the translation memory, you can start using it to translate project rows. The usage is very easy: just select a translation cell and press F2, or start typing. Soluling uses translation memory in the background to find suitable translations for the selected cell. If found, the application shows a candidate list that shows the available matches sorted by the match percent. The search might take a few seconds, and the candidate list will be updated every time the background process finds a match. The perfect match (if any) comes instantly following possible fuzzy matches. Depending on the size of your translation memory and your configuration, the search process can take anything between milliseconds to several seconds. The search process is working on a background thread, so it does not prevent you from normally using the application. If you select another cell and there is an ongoing search, it will be terminated, and a new search starts.
In addition to the above interactive mode, Soluling also supports the batch mode, where you can translate all strings of the project or the currently visible strings. Right-click the language column header and choose to Translate with Translation Memory | <translation memory you want to use>. Soluling shows a dialog where you select the scope. Check All rows to translate all rows. Check Only row of the current view to translate only those rows that belong to the current view. To add translations to the translation memory, right-click the language column header and choose Save to Translation Memory | <translation memory you want to use>.
You can add any number of translation memories. New translation memory can either be a local translation memory that exists on your computer, and only you use it, or a translation memory can exist on a server or the cloud where the whole translation team can share the same translations. A local translation memory uses an embedded SQLite database. The local translation memory is restricted to a single user. If any users want to share the same translation memory, you should create a translation memory into a server database or into the cloud. If you are using a server database, you can use either MySQL or SQL Server databases.
When using the interactive translation memory, Soluling uses only those translation memories that are currently enabled for the project. You can configure the settings from the project settings. Right-click the project root in the project tree and choose Options. Then select the Translation memory sheet. The following image shows a situation where you have four translation memories configured in Soluling, but only Local and Microsoft are enabled for this project.
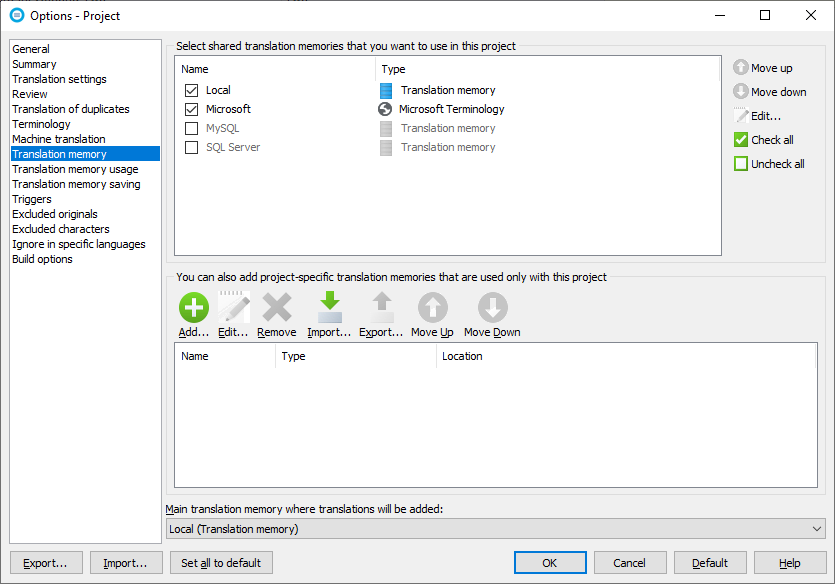
The lower half of the sheet lets you configure translation memories that are specific for this project only.
The default way to add existing translations into translation memory is to add the translations from a file to the selected translation memory. However, you can also add the translation file to the top level without adding the translation into any translation memory. In this case, Soluling creates a shadow translation memory database (CacheTranslationMemory.db) and add the translations from the file(s) into that translation memory database. The shadow translation memory contains all the files you have added into the top level of the translation memory list.
What is the difference between a termbase, translation memory, existing translations, and machine translator?
![]() Copyright © 2016-2026 Soluling Oy
Copyright © 2016-2026 Soluling Oy